

Choosing the Right LLM: A Task-Based Guide to the Most Proficient AI Models According to the LMArena Leaderboard
By Professor Moustapha Diack – SMED, SUBR - Digital Education Consulting (DEC)

Introduction
In an era where generative AI is redefining productivity, creativity, education, and research, Large Language Models (LLMs) have become indispensable tools. Yet, for most users, choosing the right LLM can be a confusing process.
To help navigate this landscape, this article presents a detailed analysis of leading LLMs—based on the most trusted open benchmark available today: the LMArena AI Leaderboard (https://lmarena.ai/leaderboard). We explain the criteria used to evaluate these models and match each to appropriate tasks, providing a structured guide for researchers, educators, developers, and the public.
What is LMArena?
LMArena (Language Model Arena) is a crowdsourced benchmarking platform maintained by LMSYS.org and hosted on Hugging Face. Unlike static academic benchmarks, LMArena evaluates LLMs based on real-time human preferences, where users compare blind responses from two models and vote for the better answer.
This approach allows LMArena to evaluate not just factual knowledge but also how well models meet human expectations for helpfulness, honesty, clarity, creativity, and more.

Evaluation Criteria

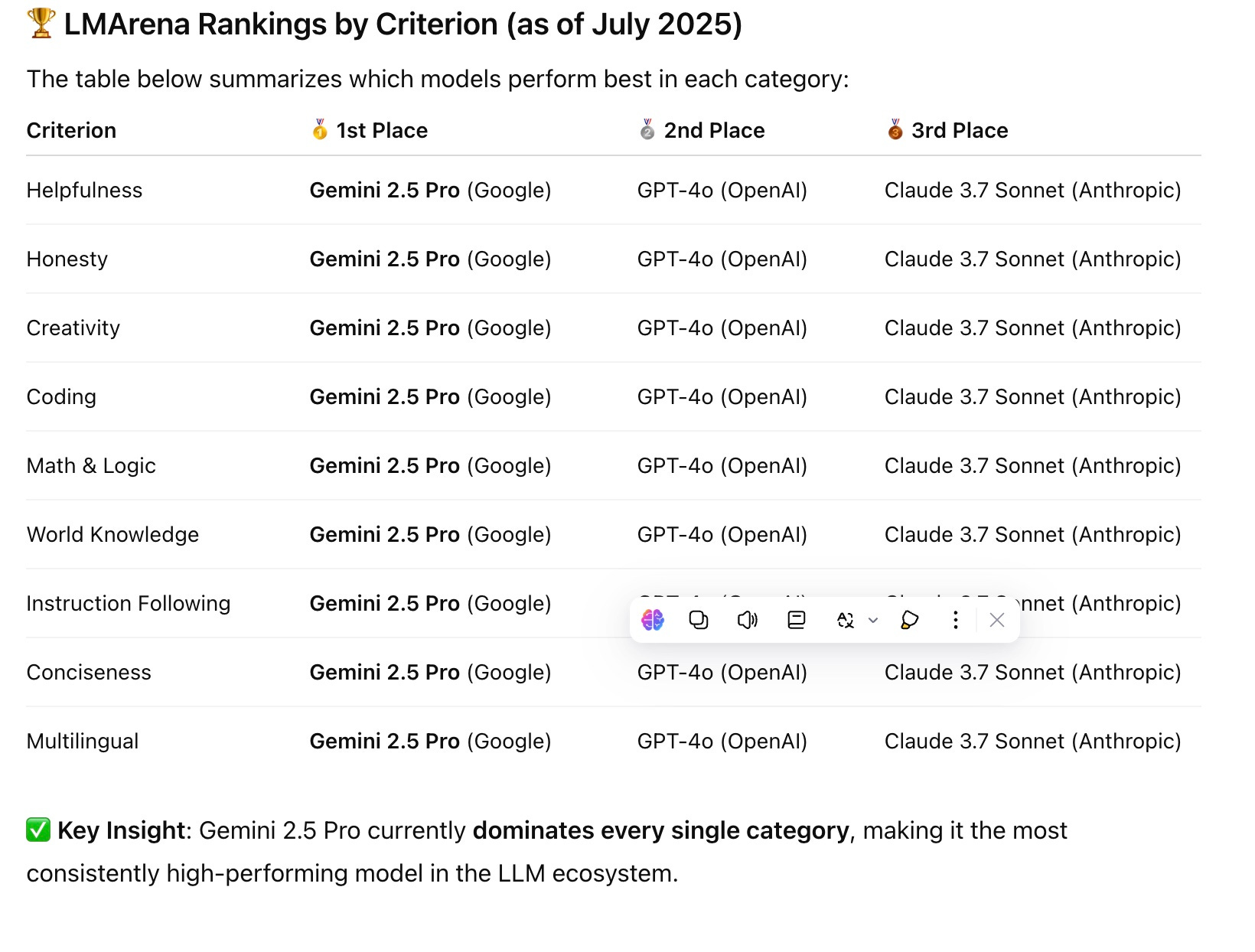
LLM Arena Ranking
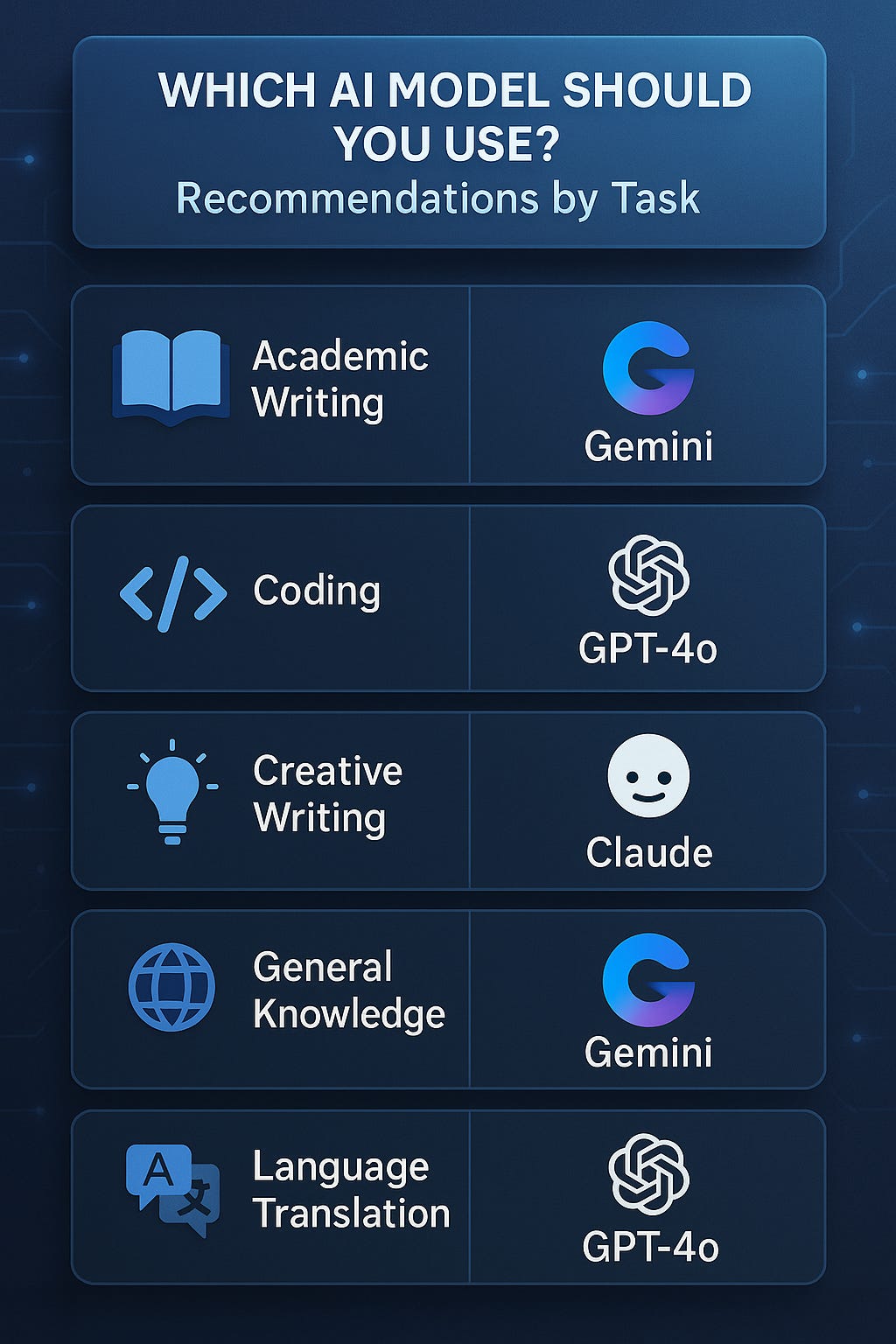
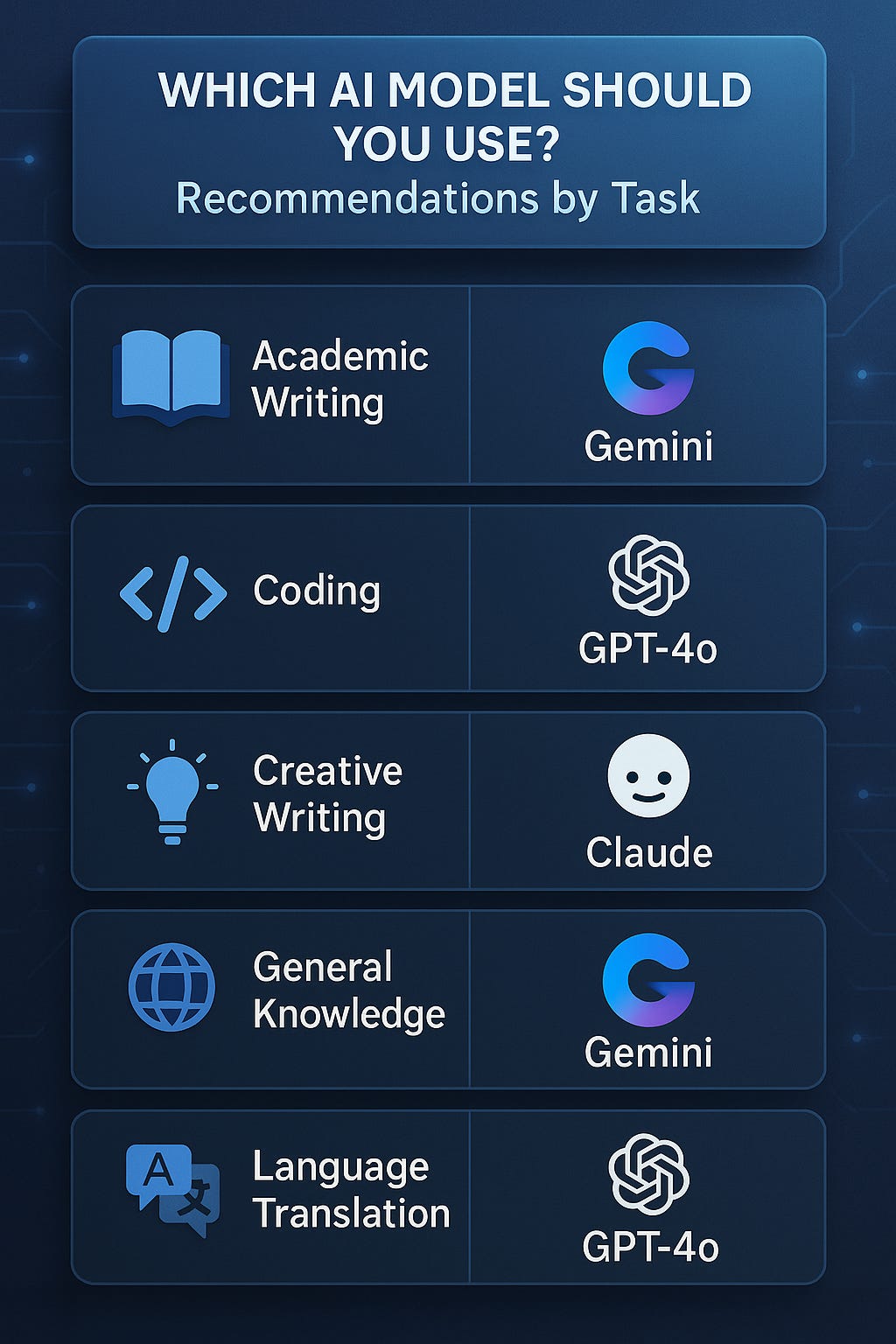
Recommendation

Practical Guidelines for Selection
If you're...
An educator → Use Gemini or GPT‑4o for accurate and clear explanations
A developer → Use Gemini 2.5 Pro for code-heavy tasks
A multilingual communicator → Use Gemini 2.5 Pro
A student on a budget → Start with GPT‑4o (ChatGPT free tier) or Claude 3.7 on Poe
A creative writer → Test both Gemini 2.5 and Claude 3.7 for tone and style differences


Critical Reflection on the Benchmark
While LMArena offers real-world insight, some experts caution that:
Models submitted may be experimental or optimized, not identical to public versions.
Some responses may be biased toward popular styles that win votes but reduce nuance.
Thus, users should combine LMArena rankings with their own testing, especially for domain-specific applications.
Conclusion
Choosing the right LLM shouldn't be a guessing game. Thanks to the LMArena leaderboard, we now have a community-driven, task-sensitive understanding of how the top models compare. Whether you’re writing code, translating languages, or composing a poem, this guide can help you select the most proficient and appropriate LLM for your needs.
➡️ Visit: https://lmarena.ai/leaderboard
➡️ More rankings: Hugging Face Arena

Professor Moustapha Diack, affiliated with the Department of Science and Mathematics Education (SMED) at Southern University in Baton Rouge, Louisiana, leads the Diack Research Network.
He also serves as Executive Director of Digital Education Consulting (DEC), an organization committed to inclusive and ethical artificial intelligence for education and sustainable development, particularly in Africa.